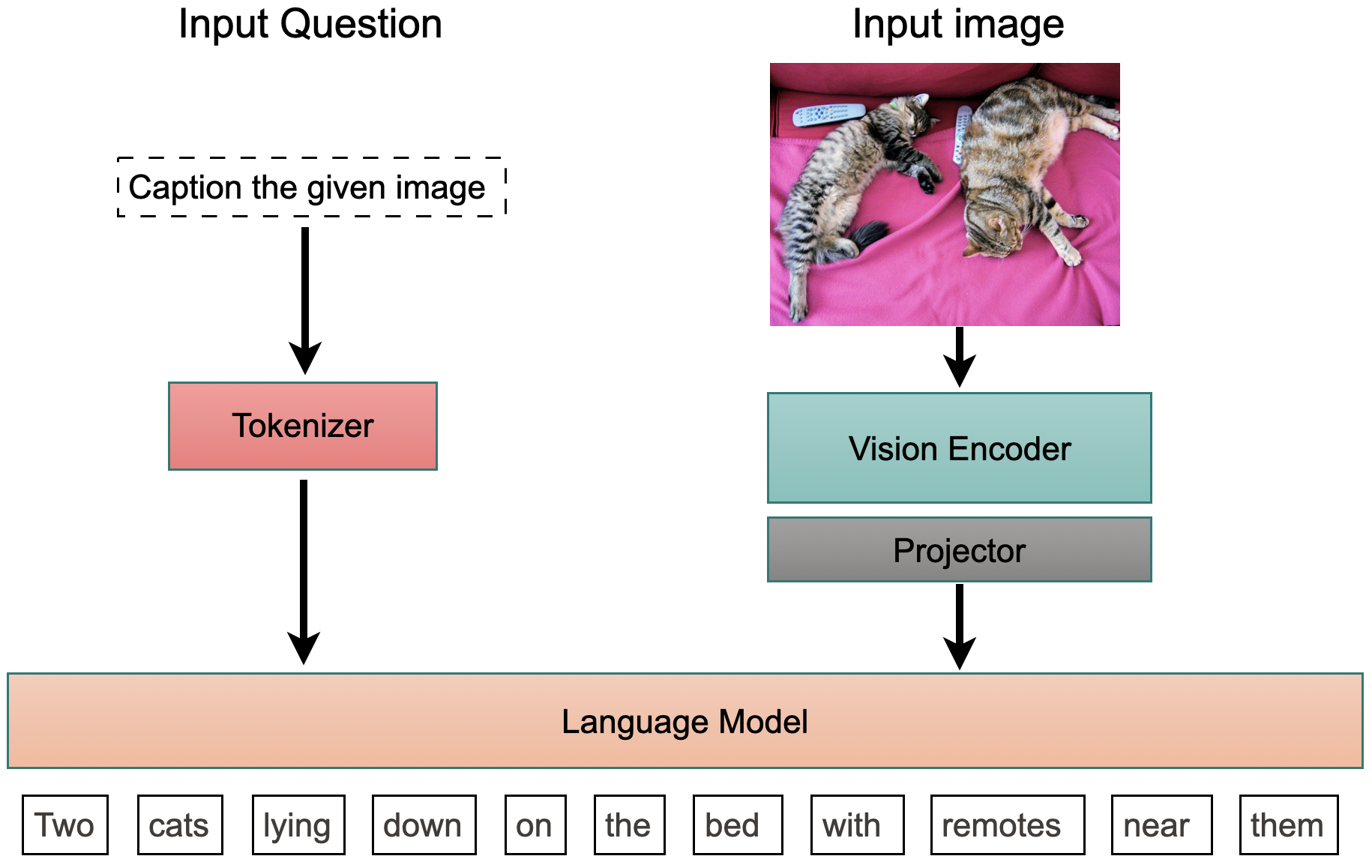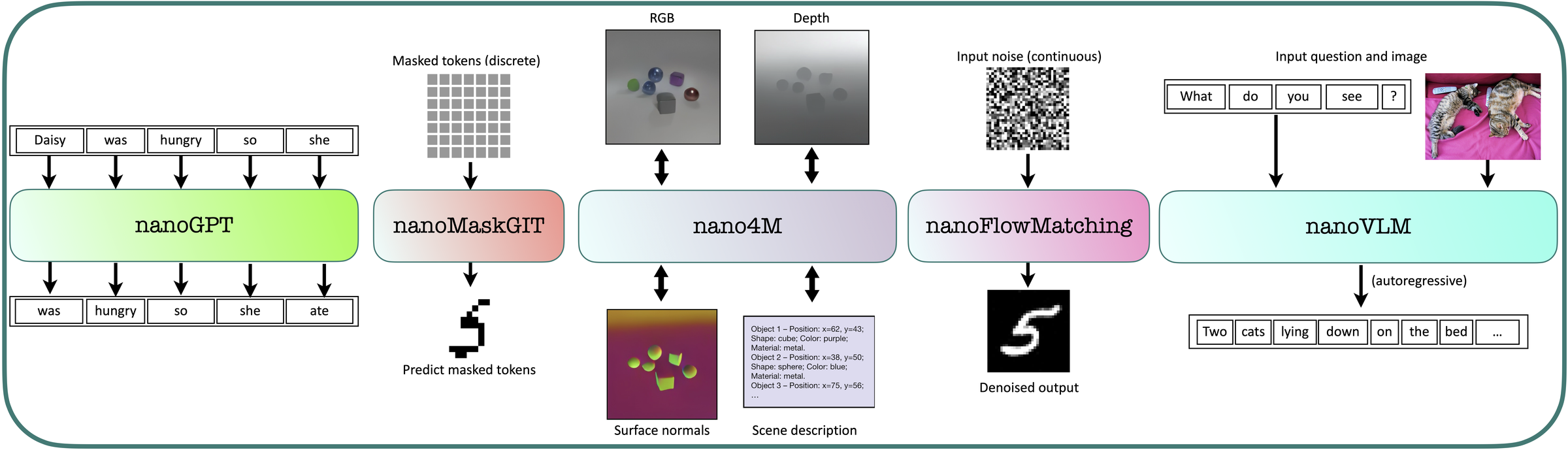
01
nanoGPT
Autoregressive transformer for language & image generation
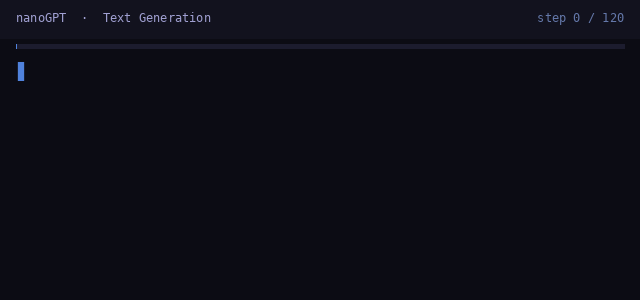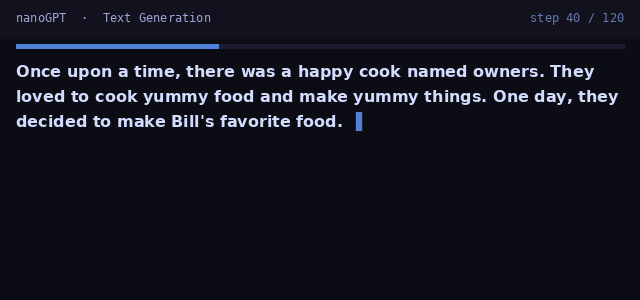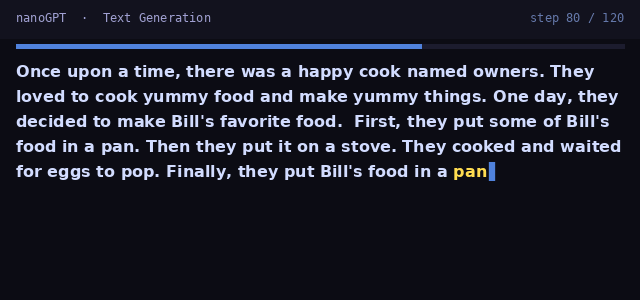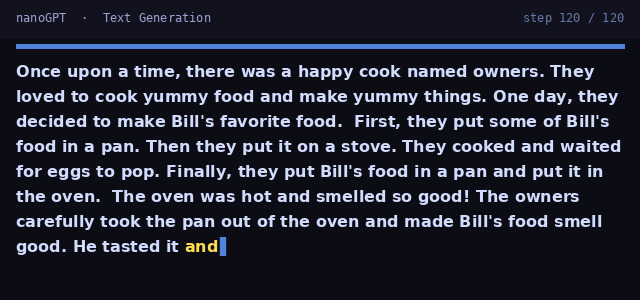
Start with the foundation: a decoder-only transformer trained next-token prediction on TinyStories and MNIST. Implement attention, the transformer trunk, and efficient generation with a KV-cache.